hashtable
SGI hashtable基于质数桶和链表,支持插入扩容,预定义部分哈希函数,其他类型需用户自定义,采用迭代器遍历,保障高效与稳定。
hashtable
Hashtable 的桶(buckets)与节点(nodes)
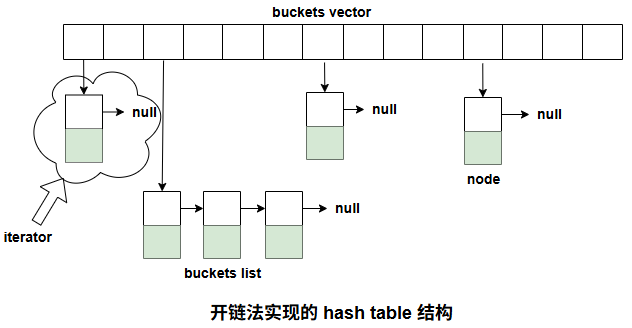
- 在 SGI STL 的源码中,哈希表内部的数组单元称为桶(bucket)。
- 每个桶不仅是一个简单的节点,而是维护了一个链表(linked list),存储所有哈希值映射到该桶的元素。
- 链表中的每个元素称为节点(node)。
节点定义
1
2
3
4
5
template <class Value>
struct __hashtable_node {
__hashtable_node* next; // 指向下一个节点的指针
Value val; // 节点存储的值
};
- 注意:哈希表中桶维护的链表不是使用 STL 的
list或slist,而是自行维护的上述节点结构。 - 桶的集合体则用
vector来实现,支持动态扩容和索引访问。
hashtable 的迭代器
Hashtable迭代器定义与实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {
// 关联的哈希表类型
typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> hashtable;
// 迭代器自身类型
typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> iterator;
// 常量迭代器类型(只读)
typedef __hashtable_const_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> const_iterator;
// 哈希表节点类型
typedef __hashtable_node<Value> node;
// 迭代器类别,哈希表迭代器是单向前向迭代器
typedef std::forward_iterator_tag iterator_category;
typedef Value value_type; // 迭代器访问的值类型
typedef ptrdiff_t difference_type; // 迭代器间距的差值类型
typedef size_t size_type; // 大小类型
typedef Value& reference; // 迭代器解引用返回引用
typedef Value* pointer; // 迭代器指针类型
node* cur; // 当前迭代器所指向的节点指针
hashtable* ht; // 指向哈希表对象的指针,方便跨桶访问
// 构造函数,传入当前节点和所属哈希表指针
__hashtable_iterator(node* n, hashtable* tab) : cur(n), ht(tab) {}
// 默认构造函数
__hashtable_iterator() {}
// 解引用操作,返回当前节点的值
reference operator*() const { return cur->val; }
// 指针访问操作,返回当前节点的值的地址
pointer operator->() const { return &(operator*()); }
// 前置++运算符,实现迭代器前进
iterator& operator++();
// 后置++运算符,实现迭代器前进,返回旧值
iterator operator++(int);
// 判断两个迭代器是否相等,比较当前节点指针
bool operator==(const iterator& it) const { return cur == it.cur; }
// 判断两个迭代器是否不等,比较当前节点指针
bool operator!=(const iterator& it) const { return cur != it.cur; }
};
迭代器前进操作 operator++()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template <class V, class K, class HF, class ExK, class EqK, class A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>&
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++() {
const node* old = cur;
cur = cur->next; // 尝试移动到当前链表的下一个节点
// 如果当前链表到尾了,跳到下一个非空桶的头节点
if (!cur) {
size_type bucket = ht->bkt_num(old->val); // 计算当前元素对应的桶号
while (!cur && ++bucket < ht->buckets.size())
cur = ht->buckets[bucket]; // 跳转到下一个桶的链表头
}
return *this;
}
迭代器后置++操作
1
2
3
4
5
6
7
template <class V, class K, class HF, class ExK, class EqK, class A>
inline __hashtable_iterator<V, K, HF, ExK, EqK, A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++(int) {
iterator tmp = *this;
++(*this); // 调用前置++
return tmp;
}
- 哈希表迭代器需要同时记录当前节点(
cur)和所属哈希表指针(ht)。 - 前进时,先尝试沿当前桶的链表用
next指针前进。 - 如果链表末尾,则跳转到哈希表的下一个非空桶的链表头。
- 哈希表迭代器不支持后退操作(无
operator--),也没有定义逆向迭代器。
hashtable 的数据结构
定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc = alloc>
class hashtable;
// ...
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
class hashtable {
public:
typedef HashFcn hasher; // 哈希函数类型(计算键的哈希值)
typedef EqualKey key_equal; // 判断两个键是否相等的函数类型
typedef size_t size_type; // 容量和计数的无符号整数类型
private:
// 三个函数对象(仿函数)
hasher hash; // 用于计算键对应的哈希值
key_equal equals; // 用于判断两个键是否相等
ExtractKey get_key; // 从存储的 Value 中提取对应 Key 的仿函数
typedef __hashtable_node<Value> node; // 哈希表中节点的类型定义
typedef simple_alloc<node, Alloc> node_allocator; // 节点分配器,使用指定的内存分配策略
// 桶的集合,使用 vector 存储,元素是指向节点的指针
// 每个桶头指向该桶对应链表的第一个节点(或为空)
vector<node*, Alloc> buckets;
size_type num_elements; // 当前哈希表中元素的总数
public:
// 返回当前桶的数量,即 buckets 容器的大小
size_type bucket_count() const { return buckets.size(); }
// 其他成员函数和接口略...
};
- hash、equals、get_key 是三个关键的仿函数,用来完成哈希映射和键比较;
- buckets 是一个动态大小的数组(vector),每个元素是桶链表头指针;
- num_elements 记录表中所有元素的数量。
hashtable的模板参数包括:
- Value:节点存储的值类型
- Key:节点的键类型
- HashFcn:计算哈希值的函数类型
- ExtractKey:从节点中提取键的函数或仿函数
- EqualKey:判断键是否相等的函数或仿函数
- Alloc:内存分配器,默认使用
std::alloc
质数桶大小与查找函数
虽然开链法不强制表格大小为质数,但SGI STL仍采用质数作为表格大小。它预先准备了28个质数(约呈倍增关系),并提供函数用于查找这28个质数中“最接近且大于指定数”的质数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// 假设 long 类型至少有32位
static const int __stl_num_primes = 28;
// 预定义的28个质数数组,用作哈希表桶的大小,数值逐渐约为两倍关系
static const unsigned long __stl_prime_list[__stl_num_primes] = {
53, 97, 193, 389, 769, 1543, 3079, 6151,
12289, 24593, 49157, 98317, 196613, 393241,
786433, 1572869, 3145739, 6291469, 12582917,
25165843, 50331653, 100663319, 201326611,
402653189, 805306457, 1610612741, 3221225473ul,
4294967291ul
};
// 查找数组中最接近且大于等于 n 的质数,
// 使用 STL 泛型算法 lower_bound 实现二分查找
inline unsigned long __stl_next_prime(unsigned long n) {
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + _s_tl_num_primes;
const unsigned long* pos = std::lower_bound(first, last, n);
// 如果找不到,则返回数组中最大的质数
return (pos == last) ? *(last - 1) : *pos;
}
// 哈希表最大桶数量,返回数组中的最大质数(4294967291)
size_type max_bucket_count() const {
return __stl_prime_list[__stl_num_primes - 1];
}
- 质数数组用于确定哈希表桶大小,保证良好散列效果。
lower_bound要求数组已排序,能快速定位目标桶大小。max_bucket_count()给出哈希表支持的最大桶数量。
hashtable 的构造与内存管理
节点配置与初始化过程
节点分配与释放
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
typedef simple_alloc<node, Alloc> node_allocator; // 节点专用分配器
// 分配新节点并构造节点值
node* new_node(const value_type& obj) {
node* n = node_allocator::allocate(); // 分配内存
n->next = 0; // next指针初始化为 nullptr
__STL_TRY {
construct(&n->val, obj); // 构造节点的值
return n;
}
__STL_UNWIND(node_allocator::deallocate(n)); // 构造失败时释放内存
}
// 释放节点
void delete_node(node* n) {
destroy(&n->val); // 析构节点的值
node_allocator::deallocate(n); // 释放内存
}
哈希表初始化示例
1
2
3
4
5
6
// 构造一个初始大小为 50 的哈希表
hashtable<int, int, hash<int>, identity<int>, equal_to<int>, alloc>
iht(50, hash<int>(), equal_to<int>());
cout << iht.size() << endl; // 输出当前元素数量,初始为 0
cout << iht.bucket_count() << endl; // 输出桶数量,实际为 53(最接近且大于50的质数)
构造函数及初始化桶过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
hashtable(size_type n,
const HashFcn& hf,
const EqualKey& eql)
: hash(hf), equals(eql), get_key(ExtractKey()), num_elements(0) {
initialize_buckets(n);
}
void initialize_buckets(size_type n) {
const size_type n_buckets = next_size(n); // 查找最接近且大于 n 的质数作为桶数
buckets.reserve(n_buckets); // 为 buckets vector 预留空间
buckets.insert(buckets.end(), n_buckets, (node*)0); // 初始化所有桶指针为空(nullptr)
num_elements = 0; // 初始化元素数量为 0
}
next_size(n)利用预定义质数表,返回最接近且大于n的质数,保证哈希表桶大小合理。1 2 3 4
// 返回最接近且大于等于 n 的质数,用于确定桶的大小 size_type next_size(size_type n) const { return __stl_next_prime(n); }
buckets使用vector<node*>存储桶链表头指针,初始都设为空指针。节点分配器负责节点内存的分配与释放,保障内存安全。
哈希表无默认构造函数,初始化时需指定桶的初始大小。
插入操作与表格重整
插入元素(不允许重复)
1
2
3
4
5
// 插入元素obj,保证不重复
pair<iterator, bool> insert_unique(const value_type& obj) {
resize(num_elements + 1); // 判断是否需要扩容,若需要则重建表格
return insert_unique_noresize(obj); // 不扩容时直接插入
}
判断是否需要重建表格(resize)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::resize(size_type num_elements_hint) {
// 判断是否需要重建哈希表:
// 依据是(新增元素计入后)元素个数是否超过当前桶数
// 也就是说,每个桶平均最多装一个元素,超过就扩容
const size_type old_n = buckets.size();
if (num_elements_hint > old_n) {
// 找到合适的新桶数(下一个质数)
const size_type n = next_size(num_elements_hint);
// 如果新桶数确实比旧桶数大,才进行扩容重建
if (n > old_n) {
// 创建新的桶数组,全部初始化为空指针
vector<node*, A> tmp(n, (node*)0);
__STL_TRY {
// 遍历旧桶中每一个桶
for (size_type bucket = 0; bucket < old_n; ++bucket) {
node* first = buckets[bucket]; // 该桶链表头节点
// 遍历该桶链表的每一个节点
while (first) {
// 计算该节点在新桶中的位置
size_type new_bucket = bkt_num(first->val, n);
// (1) 先保存当前节点的下一个节点,方便后续遍历
buckets[bucket] = first->next;
// (2)(3) 将当前节点插入到新桶链表头部
first->next = tmp[new_bucket];
tmp[new_bucket] = first;
// (4) 继续处理旧桶链表的下一个节点
first = buckets[bucket];
}
}
// 交换新旧桶数组,旧桶空间由tmp自动释放
buckets.swap(tmp);
// 注意:swap后,buckets的大小变为新桶大小
// tmp变成旧桶数组,超出作用域后自动析构释放内存
}
__STL_UNWIND(/* 异常处理,见STL实现细节 */);
}
}
}
- 负载因子(load factor)≥ 1 就触发扩容
- SGI hashtable 的设计比较保守,不像现代实现那样允许负载因子 0.7 或 0.75,它直接规定 一个桶平均只放一个元素。
无需扩容情况下的插入操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
template <class V, class K, class HF, class Ex, class Eq, class A>
pair<typename hashtable<V, K, HF, Ex, Eq, A>::iterator, bool>
hashtable<V, K, HF, Ex, Eq, A>::insert_unique_noresize(const value_type& obj) {
// 计算元素应当放入的桶索引
const size_type n = bkt_num(obj);
// 获取该桶对应链表的头节点指针
node* first = buckets[n];
// 遍历该桶链表,检查是否已有相同键的元素
for (node* cur = first; cur; cur = cur->next) {
// 如果发现键相同,则不插入,返回失败
if (equals(get_key(cur->val), get_key(obj))) {
return pair<iterator, bool>(iterator(cur, this), false);
}
}
// 不存在相同键,创建新节点
node* tmp = new_node(obj);
// 新节点插入链表头部
tmp->next = first;
buckets[n] = tmp;
// 元素计数增加
++num_elements;
// 返回新节点的迭代器和成功标志
return pair<iterator, bool>(iterator(tmp, this), true);
}
- insert_unique:插入元素,先调用
resize判断是否需要扩容,再调用不扩容时的插入函数。 - resize:当元素数超过桶数时,将桶数扩展到更大的质数,并重新分配所有节点。
- insert_unique_noresize:不扩容情况下,检查桶链表是否有重复键,无重复则插入链表头。
resize() 中表格重建的节点迁移操作步骤
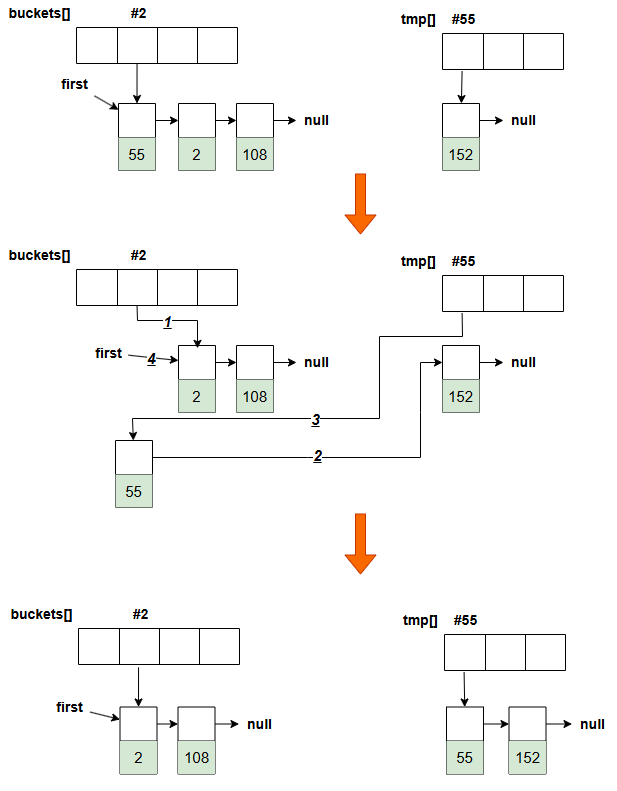
更新旧桶链表头 将旧桶当前指针指向链表中的下一个节点,方便后续迭代处理:
1
buckets[bucket] = first->next;
插入节点到新桶链表头 将当前节点插入到新桶对应链表的头部:
1 2
first->next = tmp[new_bucket]; tmp[new_bucket] = first;
准备处理旧桶链表的下一个节点 更新处理指针,继续遍历旧桶链表:
1
first = buckets[bucket];
插入元素(允许重复)
插入入口(带扩容判断)
1
2
3
4
5
// 插入元素,允许重复键
iterator insert_equal(const value_type& obj) {
resize(num_elements + 1); // 判断是否需要扩容,必要时重建表格
return insert_equal_noresize(obj); // 不扩容时直接插入
}
不扩容时插入实现(允许重复键)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
template <class V, class K, class HF, class Ex, class Eq, class A>
typename hashtable<V, K, HF, Ex, Eq, A>::iterator
hashtable<V, K, HF, Ex, Eq, A>::insert_equal_noresize(const value_type& obj) {
size_type n = bkt_num(obj); // 计算元素所属桶号
node* first = buckets[n]; // 桶链表头节点
// 遍历桶链表,寻找相同键的节点
for (node* cur = first; cur; cur = cur->next) {
if (equals(get_key(cur->val), get_key(obj))) {
// 发现相同键,插入到该节点后面
node* tmp = new_node(obj);
tmp->next = cur->next;
cur->next = tmp;
++num_elements; // 元素总数加一
return iterator(tmp, this);
}
}
// 没有找到相同键,插入链表头部
node* tmp = new_node(obj);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return iterator(tmp, this);
}
允许重复键:遇到相同键时,不拒绝插入,而是把新节点插入到该节点之后。
遍历链表查找同键:找到第一个相同键节点后插入。
为什么放“后面”而不是前面?
- 保持插入顺序 SGI hashtable 是有“稳定遍历”特性的,即遍历顺序和插入顺序一致(同一个桶里,先插入的元素先遍历到)。 如果把新元素插在链表前面,会破坏原有的顺序。
- 便于批量插入时的顺序一致性 这样
equal_range返回的区间顺序和用户插入顺序一致。
所以,它在找到相同键的节点时,会在其后面插入新节点,而不是前面。
未找到同键:新节点插入链表头部。
更新元素数量:每次插入后,
num_elements自增。
元素落脚桶的计算(bkt_num)
哈希表需要确定元素应放入哪个桶中(bucket),这项工作由 bkt_num 函数完成。SGI STL 将这一功能封装为多种重载形式,最终调用哈希函数并对桶数取模。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 版本1:根据元素值和桶数量计算桶编号
size_type bkt_num(const value_type& obj, size_t n) const {
// 先提取键值,再调用版本4完成计算
return bkt_num_key(get_key(obj), n);
}
// 版本2:仅根据元素值计算桶编号,使用当前桶数量
size_type bkt_num(const value_type& obj) const {
// 先提取键值,再调用版本3完成计算
return bkt_num_key(get_key(obj));
}
// 版本3:仅根据键值计算桶编号,使用当前桶数量
size_type bkt_num_key(const key_type& key) const {
return bkt_num_key(key, buckets.size());
}
// 版本4:根据键值和桶数量计算桶编号,核心实现
size_type bkt_num_key(const key_type& key, size_t n) const {
// 调用哈希函数,取模桶数量,返回桶索引
return hash(key) % n;
}
get_key(obj):从元素中提取键值。hash(key):调用哈希函数,返回哈希值。% n:对桶数量取模,确定桶索引。- 通过多层函数调用,方便支持不同参数输入及对特殊类型(如字符串)的处理。
复制(copy_from)与清空(clear)操作
由于哈希表由 vector 和链表(linked list)组成,复制和清空都需要注意节点的正确释放和重新分配。
清空函数 clear()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::clear() {
// 遍历所有桶
for (size_type i = 0; i < buckets.size(); ++i) {
node* cur = buckets[i];
// 删除该桶链表中所有节点
while (cur != 0) {
node* next = cur->next;
delete_node(cur); // 释放当前节点内存
cur = next; // 继续下一个节点
}
buckets[i] = 0; // 桶指针置空
}
num_elements = 0; // 元素数量清零
// 注意:buckets vector 本身空间未释放,仍保持原大小
}
复制函数 copy_from(const hashtable& ht)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::copy_from(const hashtable& ht) {
// 先清空当前哈希表内容,释放内存
buckets.clear();
// 保留空间,使 buckets 大小至少和 ht 一样
buckets.reserve(ht.buckets.size());
// 插入与 ht 桶数量相同的空桶指针(nullptr)
buckets.insert(buckets.end(), ht.buckets.size(), (node*)0);
__STL_TRY {
// 遍历对方的每个桶
for (size_type i = 0; i < ht.buckets.size(); ++i) {
if (const node* cur = ht.buckets[i]) {
// 复制第一个节点
node* copy = new_node(cur->val);
buckets[i] = copy;
// 复制该桶链表剩余节点
for (node* next = cur->next; next; cur = next, next = cur->next) {
copy->next = new_node(next->val);
copy = copy->next;
}
}
}
// 更新元素数量
num_elements = ht.num_elements;
}
__STL_UNWIND(clear()); // 异常处理,确保异常时清理已分配资源
}
clear():逐桶遍历,删除所有节点并将桶指针置空,但不释放桶的空间。copy_from():先清空自身,扩容桶向量,逐桶复制节点内容,保持链表结构一致。- 使用
__STL_TRY和__STL_UNWIND宏处理异常安全,防止部分复制时内存泄漏。
hash functions
《stl_hash_fun.h》中定义了多个现成的哈希函数,全部是仿函数。SGI STL通过 bkt_num() 函数调用这些哈希函数,得到一个适合做模运算的值,用于确定元素位置。对于整型(如 char、int、long),哈希函数通常直接返回原值;而对于字符串类型(const char*),则设计了专门的转换函数来计算哈希值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
// 定义于 <stl_hash_fun.h> 中的哈希结构体模板,针对不同类型实现哈希函数
// 通用模板,未具体实现,留给后续特化
template <class Key> struct hash { };
// 字符串哈希计算函数(用于 const char*)
inline size_t __stl_hash_string(const char* s) {
unsigned long h = 0;
// 遍历字符串每个字符,累积哈希值
for (; *s; ++s)
h = 5 * h + *s;
return size_t(h);
}
// 针对 char* 类型的哈希特化,调用字符串哈希函数
__STL_TEMPLATE_NULL struct hash<char*> {
size_t operator()(const char* s) const { return __stl_hash_string(s); }
};
// 针对 const char* 类型的哈希特化,调用字符串哈希函数
__STL_TEMPLATE_NULL struct hash<const char*> {
size_t operator()(const char* s) const { return __stl_hash_string(s); }
};
// 以下是针对各种整型的哈希特化,直接返回值本身作为哈希值
__STL_TEMPLATE_NULL struct hash<char> {
size_t operator()(char x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned char> {
size_t operator()(unsigned char x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<signed char> {
size_t operator()(signed char x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<short> {
size_t operator()(short x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned short> {
size_t operator()(unsigned short x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<int> {
size_t operator()(int x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned int> {
size_t operator()(unsigned int x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<long> {
size_t operator()(long x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned long> {
size_t operator()(unsigned long x) const { return x; }
};
由此可见,SGI hashtable 只能直接处理其内部预定义的基本类型(如整数型、C 风格字符串指针等)。对于当时未内置的类型(如 std::string、double、float),用户需要自行定义对应的哈希函数。而在现代 C++(C++11 及以后)中,标准库已经在 std::hash 中为这些常见类型(如 std::string、浮点数等)提供了默认的哈希函数,因此在使用 std::unordered_map 等容器时可以直接处理这些类型,无需额外定义哈希函数。
对于自定义类型,则依然需要用户实现 std::hash<T> 特化或提供自定义哈希函数对象,才能用于哈希容器。